
Refactoring : par où commencer ?

Temps de lecture estimé : 3min
Nous avons vu dans le denier post l’importance du refactoring pour gérer la dette technique d’un projet.
Mais devant l’ampleur de la tâche, comment savoir où commencer ?
Dans cet article, je vous propose donc un dispositif qui peut vous aider à déterminer les zones de codes candidates à un refactoring à forte valeur ajoutée.
Qu’est-ce que j’entends par “forte valeur ajoutée” ?
Eh bien tout simplement le fait de ne pas tomber dans un effet tunnel et se retrouver à passer des semaines, voire des mois à refactorer du code legacy, pour très peu de gain de productivité.
Car oui, c’est finalement le but d’un refactoring de code legacy : faire en sorte que l’équipe gagne en productivité à moyen terme.
La dette technique devient handicapante quand les développeurs ont peur de toucher telle ou telle partie de code, car ils ne sont pas certains de ne rien casser.
Le problème, c’est que s’il y a beaucoup de dette technique dans ces zones-là, c’est souvent parce que ce sont des endroits où beaucoup de développeurs interviennent régulièrement et souvent dans l’urgence, créant ainsi patch sur patch et faisant naître ce monstre de dette technique que l’on cherche à éradiquer ici.
Dans sa Master Class sur la réduction de la dette technique, Michael Feathers propose une heuristique sous forme de graphique pour permettre d’éclairer ces choix de refactoring à la lumière, donc, de deux critères :
la complexité du code
la fréquence de changement de ce code
On peut par exemple utiliser le nombre de commits concernant telle ou telle partie du code comme unité de “fréquence de changement”.
Pour la complexité du code c’’est beaucoup plus subjectif. Il est possible d’utiliser tout type d’indicateurs qui parait le plus pertinent pour l’équipe et qui semble s’aligner sur son ressentie. On peut par exemple utiliser la notion de complexité cyclomatique comme unité.
Il s’agit maintenant de faire un graphique très simple avec en abscisse le nombre de commits (la fréquence de changement du code) et en ordonnée la complexité du code :
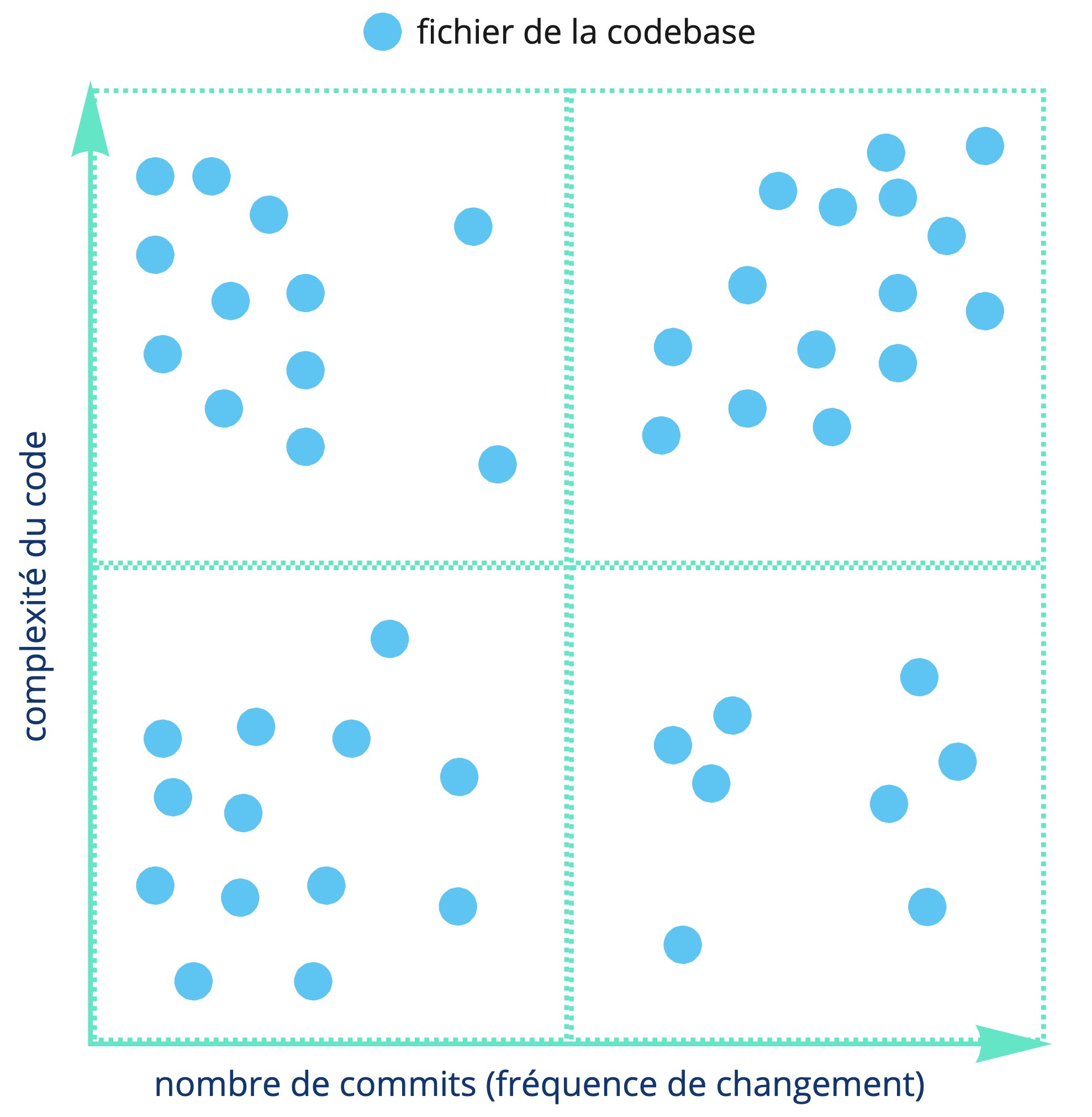
Quatre zones se dessinent alors :
La zone tout en bas à droite contient le code qui a très peu de complexité, mais qui change régulièrement. Ce sont sûrement des abstractions dont le contrat change à mesure que le projet évolue ou simplement des jeux de données ou de la configuration volatile.
Tout en bas à gauche se trouve la zone où le code est à la fois peu complexe et où il change très peu. Rien de particulier à dire ici si ce n’est que c’est donc du code qui ne semble pas freiner la productivité de l’équipe. RAS donc.
Tout en haut à gauche, c'est le code très complexe et qui n’est pas souvent modifié, principalement parce que tout le monde a peur d’y toucher à cause des potentiels effets de bord que cela pourrait engendrer.
Et enfin, la zone tout en haut à droite. Beaucoup de complexités et beaucoup de changements. C’est donc LA zone qui ralentit le plus l’équipe et sur laquelle il convient donc de se concentrer. Pour cela, il faut maintenant déterminer quelles sont les zones les plus critiques pour le métier, car ce sont les zones qui font perdre le plus d’argent à l’entreprise :
parce que les développeurs passent un temps fou à essayer de comprendre le code, et donc se retrouvent à faire des patchs dans tous les sens, ce qui ne fait qu’empirer la complexité (ah le bon vieux quick & dirty…)
parce que cela freine l’entreprise dans le développement de nouvelles fonctionnalités
En mettant en évidence ces fameux points critiques, on obtient ainsi les priorités de refactoring :
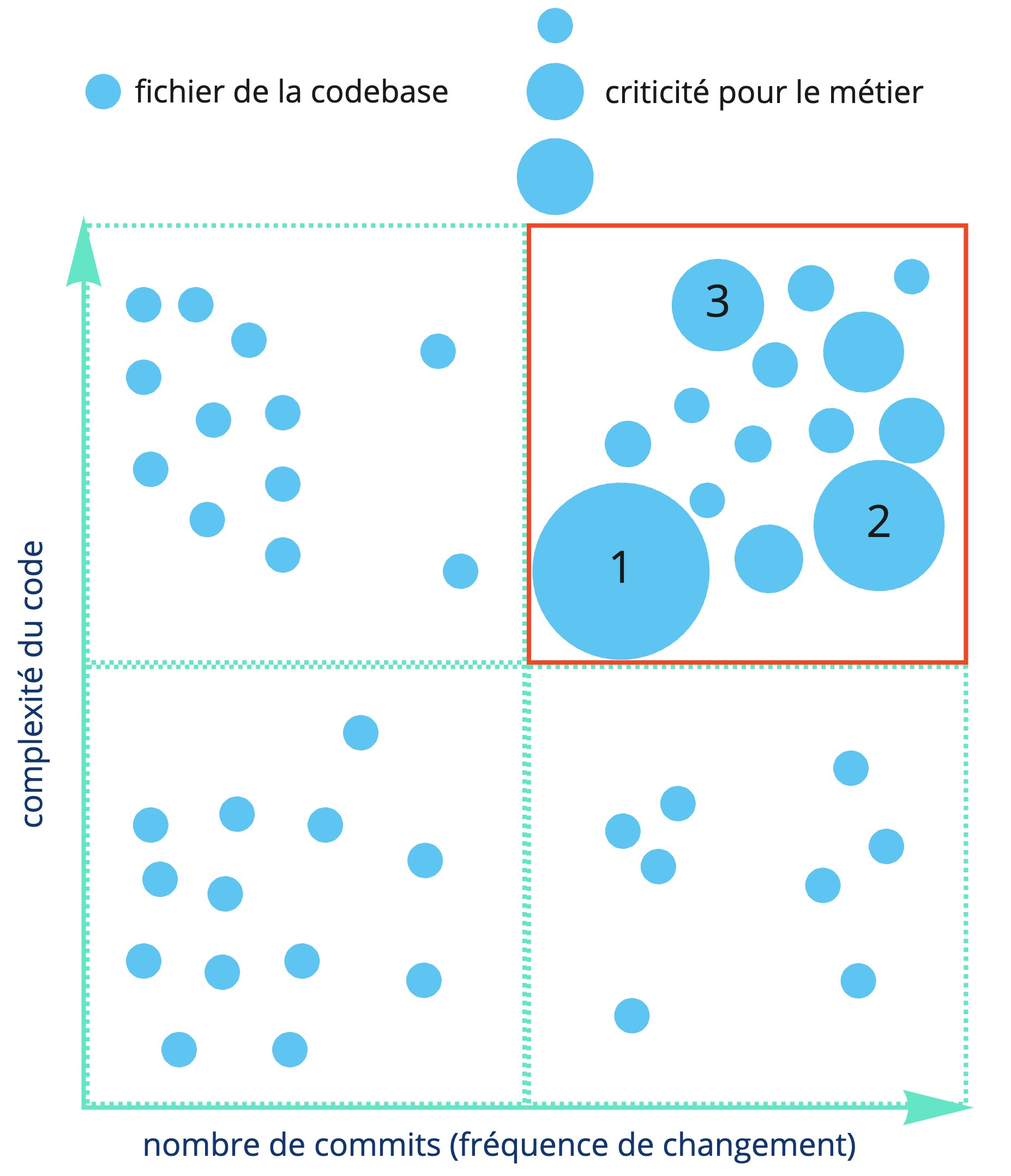
Il s’agit désormais de mettre en place un plan de refactoring ! On peut notamment s’aider pour ce faire d’outils comme le scratch refactoring et le characterization testing que l’on a vus dans le post précédent :)
On verra aussi dans le prochain post certains autres outils qui peuvent aider pour tenter de ne pas en arriver à ce point de dette technique !
En attendant :
Happy Coding !