
5 étapes simples pour structurer un bon test quand on commence le TDD
Décortiquons ensemble comment écrire petit à petit un test qui servira de structure à nos refactoring !

Hello ! Ça faisait (trop) longtemps ;)
Dans ce post j’’aimerais aujourd’hui vous partager ma façon de structurer un test quand je fais du TDD.
On va partir pour ce faire d’un use case très simple, tiré du kata Social Network :
Posting: Alice can publish messages to a personal timeline
Étape 1 : raconter l’histoire grâce à un exemple concret
La toute première étape en TDD lorsque l’on s’attaque à une nouvelle fonctionnalité, c’est de se raconter une histoire à travers un exemple concret. Pour reprendre le use case cité plus haut, on pourrait imaginer la petite histoire suivante :
Ma timeline twitter est désespérément vide, je souhaite donc envoyer un tweet "Hello world !" pour qu'on puisse le voir dans ma timeline.
➡️ La situation initiale représente ici l'état de notre système observable. Le système observable c'est la timeline d’Alice. La situation initiale décrit ainsi une timeline vide.
➡️ L'élément déclencheur est évidemment l'action exercée sur notre système observable. L'ajout d'un message sur la timeline.
➡️ La situation finale est le résultat attendu de notre système observable : la timeline d’Alice contient son message.
L’objectif de notre test unitaire va donc être de raconter cette histoire, tout en ne figeant aucune implémentation particulière. Ainsi, sa seule raison de changer sera si l’histoire doit changer.
Maintenant que l’on a cet exemple en tête, on peut passer à son “encodage” sous forme de code.
Étape 2 : Raconter l’histoire dans le code en écrivant un test “DAMP”
L’acronyme DAMP signifie Descriptive And Meaningful Phrase.
Le plus important est ici de pouvoir être capable de “lire” notre histoire, rien qu’en lisant le code de notre test, sans trop de détails techniques.
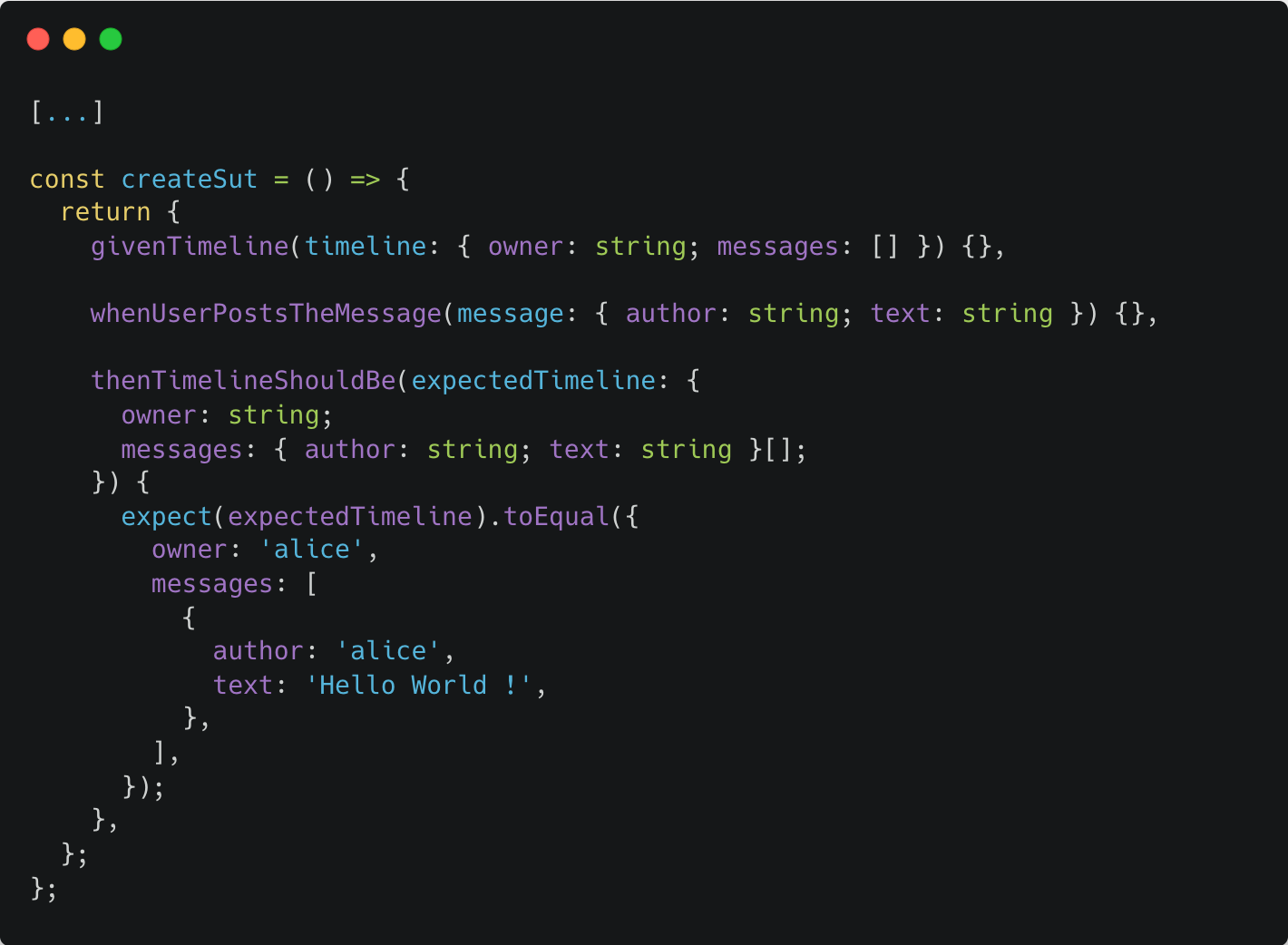
Étant donné que nous n’avons pour l’instant écrit aucun code, aucun détails technique ne peut venir nous polluer :) Voici ce à quoi on pourrait arriver :

Cette façon de faire, avec l’objet sut m’est très personnelle, “sut” est l’acronyme de system under test. Je l’utilise comme un objet contextuel qui va me permettre de “ranger” tous les détails de mon test bien au chaud dedans, sans que ça vienne polluer la lecture du test.
Peu importe la manière dont vous l’écrivez, l’important à retenir ici est d’utiliser des méthodes “helpers” qui vont “raconter” l’histoire de votre test pour qu’il se lise aisément.
Afin que le code “compile”, on définit bien les différentes fonctions avec leur signature, sans se soucier d’autres choses pour le moment.
Nous avons à ce stade une structure globale de notre test qui se dessine, mais celle-ci n’est pas encore articulée. C’est-à-dire que chaque étape n’est pas logiquement connectée avec les autres pour tester l’orchestration du use case que l’on cherche à tester.
Le but des prochaines étapes va donc être de “connecter” les étapes entre elles pour avoir une structure de test bien articulée et prête à accueillir n’importe quelle implémentation. Pour cela, nous allons procéder “à l’envers”, en partant de l’étape then pour remonter jusqu’au given, pour être sûr de bien connecter l’ensemble.
Et ce faisant, il faut absolument respecter une règle : la règle de l’exhaustivité
Règle de l’exhaustivité : chaque étape doit utiliser tous les paramètres qu’elle reçoit. Dans leur intégralité.
C’est une façon de s’assurer que l’on utilise bien tous les détails de notre histoire, et c’est ce qui rend cette méthode un peu “magique”, vous allez voir ;)
Si on comprend bien la première partie de cette règle, la notion de “dans leur intégralité” est un peu plus floue. Ça va bientôt se clarifier.
Étape 3 : “Hardcoder” la valeur attendue dans l’étape then pour faire passer le test
Cette étape est très simple, mais très importante. Elle va servir de base aux étapes suivantes. L’idée est ici de faire passer le test le plus simplement possible, pour que l’étape then “supporte” la structure de notre test. C’est la raison pour laquelle on procède à l’envers, en commençant par le then pour remonter jusqu’au given.
Pour que le test soit vert le plus rapidement possible, on va tricher et retourner la valeur attendue directement :
On respecte bien la règle d’utiliser tous les arguments à notre disposition puisqu’on utilise directement l’argument expectedTimeline.
Étape 4 : Connecter le when avec le then
Cette étape consiste à connecter le when avec le then, c’est-à-dire à faire correspondre l’action sur notre système avec le résultat attendu.
L’action est ici d’ajouter un message, le résultat attendu est celui de le voir apparaître dans la timeline.
L’action la plus simple que l’on puisse faire ici est d’ajouter un tableau de messages, que l’on va utiliser dans l’étape then. On “connecte” ainsi les deux étapes, et on se rapproche un petit peu plus d’une structure de test bien articulée :

Ici encore on respecte bien la règle, on utilise l’argument message passé en paramètre.
Étape 5 : Connecter le given avec le when
Sans surprise, nous allons maintenant connecter le given avec le when. Comme précédemment, l’idée est ici d’utiliser dans l’étape when quelque chose géré depuis l’étape given.
Et c’est là que l’on comprend l’intérêt et la puissance de la règle de l’exhaustivité. Sans chercher à la respecter, voilà ce qu’on pourrait écrire :

Notez qu’ici on utilise en effet l’objet timeline, mais seulement sa propriété message ! C’est ici qu’intervient la notion “d’intégralité” de la règle. Il faut utiliser la notion de timeline dans son intégralité, et pas simplement picorer dedans un concept qui nous arrange.
Rappelez-vous : c’est notre histoire qui nous a dicté cette méthode, donc si la timeline a une propriété owner c’est qu’elle est importante, sans quoi nous n’aurions pas eu besoin de le spécifier dans l’histoire.
Du coup, le seul moyen d’embarquer toute la notion de timeline d’un coup est d’assigner directement un objet “timeline” au lieu d’un tableau de messages :

L’étape given est maintenant connectée à l’étape when, et encore mieux, on voit qu’on utilise dans les 3 étapes le même objet theTimeline… qui n’est autre que notre système observable ! C’est ainsi une indication forte que notre structure de test est cohérente !
À ce stade, nous avons ainsi un test dont la structure vérifie bien le comportement attendu. Bien entendu, quand je parle de comportement ici, je parle d’un point de vue “logique d’orchestration”. Le vrai comportement reste à implémenter, mais grâce à cette structure, vous n’aurez pas besoin de modifier votre test directement, seulement l’implémentation des étapes :)
Les étapes suivantes
Ce post n’a pas pour objectif de détailler précisément les étapes suivantes d’implémentation du comportement (ce qui est évidemment ce qui nous intéresse en premier lieu quand on veut développer une fonctionnalité).
Je ne vais donc pas rentrer dans les détails, mais voici concrètement ce qui pourrait être fait :
Faire émerger certains types
Notre structure de test fait clairement émerger des notions que l’on peut représenter sous forme de types très simples (je ne vais pas ici exposer des concepts liés au Domain-Driven Design ou autre, c’est hors sujet, donc le code est volontairement simple) :

Faire émerger la notion d’I/O pour récupérer / sauvegarder une timeline
On sait de manière évidente que l’on va avoir besoin de récupérer notre timeline, et de pouvoir la sauvegarder. Nul besoin ici de tenter de faire émerger ces objets par une démarche TDD, c’est de l’architecture logicielle, donc on se base sur nos connaissances pour écrire les objets nécessaires, dans la phase de refactoring du TDD (puisque notre test est toujours vert, je le rappelle :) ) :

Extraire la logique métier du test pour la mettre dans une classe de code de production
La logique d’orchestration est dans l’étape when actuellement. Bien sûr, si l’on veut que le code soit utile, il faut sortir cette logique dans une “vraie” classe qui pourra être pilotée par de “vrais” utilisateur, et pas juste notre test.
Ici encore, on utilise nos connaissances en architecture logicielle, pour se rendre compte que l’on a besoin ici de ce qu’on appelle un Application Service ou (Use Case) :

Et voilà ! Nous avons maintenant notre test qui vérifie bien le bon comportement de notre application :)
Conclusion
Je viens de vous présenter la façon dont je raisonne lorsque j’applique le TDD à mes projets.
Ne prenez pas ce post religieusement, c’est une méthodologie parmi d’autres, c’est la mienne, et il existe probablement des méthodologies qui correspondent mieux à votre façon de réfléchir.
Ceci étant dit, je pense tout de même que vous pouvez appliquer les principes sous-jacent peu importe la forme que ça prend.
De plus, j’ai volontairement détaillé presque à l’excès chaque étape, en pratique, avec l’expérience, ces étapes peuvent se réaliser beaucoup plus vite, voire peuvent même être sautée :)
Happy Coding !
Voici le lien vers le repo où chaque commit détaille les étapes : https://github.com/Craft-Academy/social-network-kata
Pierre.